


Spark Query Taking Forever?
Crashing With 'Out of Memory Errors' ? - WE GET IT!
INTRODUCING - KwikQuery's TabbyDB
Turbocharged fork of Apache Spark for lightning-fast queries and unstoppable data performance.
Many real-world queries take hours or fail entirely.
- Query Compile Time Is Not Even Counted In Spark UI
- More time may get spent in planning than executing for large, complex queries
- Runtime performance of nested join queries unsatisfactory.
- UI registers a query only after plan is submitted, leaving possible bottleneck hidden
- Work around suggested by providers is
disabling of rules, impacting the runtime performance.
The Result
- Wasted compute.
- Hours of delay
- Unmet SLAs
The Solution: KwikQuery's TabbyDB
- We tackle the root causes :
query plan bloat
compile-time overhead
suboptimal runtime performance of nested join queries
- Absolutely no disabling of rules!
- No code rewrites
- No cluster changes
- Dynamic file pruning using broadcast hash join data, to better run time performance
Accelerating Complex Query Execution
TabbyDB enhances Apache Spark by eliminating the performance bottlenecks, which impact intricate queries (complex case logic, extensive joins, and large query trees), resulting in speed up of execution and reduced resource consumption, enabling enterprises to handle demanding data workloads more efficiently.
Check out the performance difference between stock spark and KwikQuery's TabbyDB, by clicking the button for comparing performance. It will lead you to Zeppelin notebooks, where same query can be run on stock spark and TabbyDB. Please note that running the paragraph on stock spark may take anywhere between 5 to 12 minutes.
Performance Enhancements That Redefine Complex Query Execution
Intelligent Compile-Time Optimizations
Changing at fundamental level, the algorithm of some of the critical rules like constraints propagation, collapsing the project nodes early (in the analysis phase), minimizing the calls to hive meta store and many more thoughtful modifications, tremendously improve compile-time performance.
Advanced Broadcast Hash Join Handling
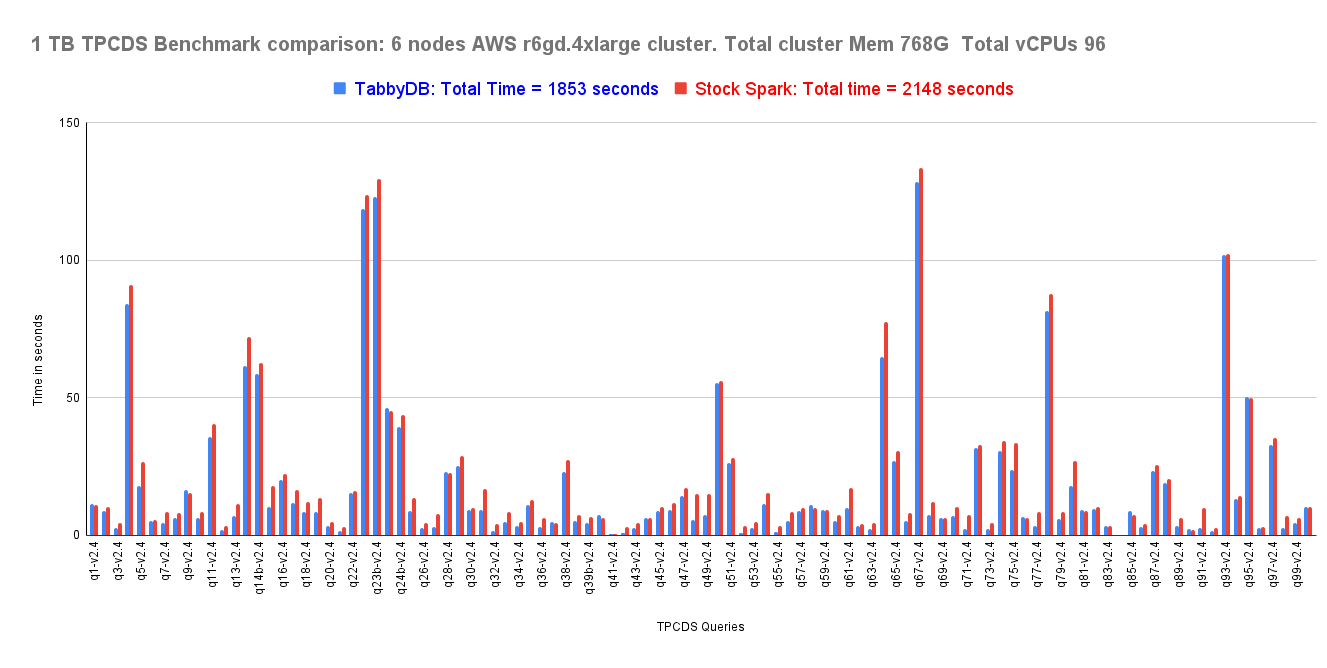
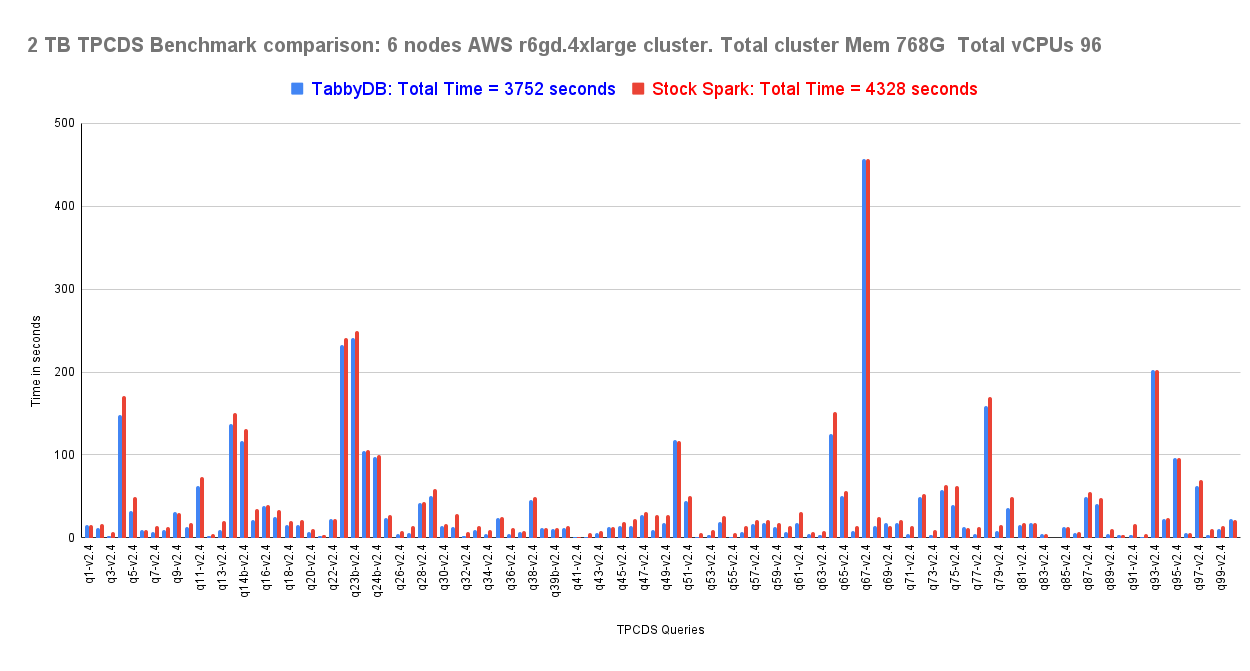
Our fork optimizes the broadcast hash joins on non partitioned columns, to do dynamic file pruning, boosting the runtime performance of nested join queries. In a limited TPCDS testing, it has shown 13% performance improvement in time taken, compared to stock spark.
Improving Cache Look Up
The cache lookup of in memory plans is made more intelligent, there by increasing the hit rate of successful lookUps. This increased sensitivity can have huge impact on runtime performance.
Scalable Query Tree Management
The new rules and algorithm change allow for collapse of the projects in the analysis phase, there by capping the tree size. This results in tremendous savings in terms of time taken to compile, preventing out of memory errors.
Seamless Integration with Apache Spark Features
While boosting performance, KwikQuery's TabbyDB, retains full compatibility with Apache Spark’s APIs and features, allowing users to leverage familiar tools with enhanced speed.
Spark SQL Modules Optimized in TabbyDB
Spark SQL Processing



TabbyDB Performance Metrics
TabbyDB transforms complex query execution by drastically reducing compile and runtime durations. Our specialized optimizations target intricate case statements, nested joins, and expansive query trees, delivering measurable improvements that empower data teams to handle demanding workloads with ease and efficiency.
N x performance improvements
TPCDS is not a realistic benchmark for performance of apache Spark as analytics engine. The complexity of SQL queries is limited due to input being a String and limits on level of nesting.
TPCDS Benchmark for 1 TB and 2TB , for Spark with Hive External non partitioned tables, 13 % improvement in execution time was seen in both the cases . This does not take into account the impact of compile time optimizations as the TPCDS queries are not that complex. Also the improvement is seen across the board ( so not an outlier effect)
Analytic queries, especially those created by some looping logic using DataFrame APIs, can become extremely large and Stock Spark is seen to take hours ( > 1 Hour to 8 hours) to compile and even then may fail with OutOfMemory.
KwikQuery's TabbyDB will be able to bring down those times to realistic levels of minutes / seconds.
For details of TPCDS Run, please see
White Papers
Issues Resolved in TabbyDB
Explore the key functional and performance issues that have been addressed in TabbyDB, enhancing your experience with complex queries.
Performance Issues
- SPARK-33152: Constraint Propagation rule causing query compilation times to run into hours.
- SPARK-36786: Inefficiency in PushDownPredicates rule affecting complex expressions.
- SPARK-44662: Dynamic file pruning for non partition column joins.
- SPARK-45373: Minimizing calls to HMS layer. Issue impacts hive metastore based tables, with query having repeated reference to the tables.
- SPARK-45866: Reuse of Exchange broken in AQE when runtime filters are pushed down to scan
- SPARK-45959: Uncapped tree size in analysis phase, causing compilation to run into hours.
- SPARK-46671: Redundant filter creation due to buggy Constraint Propagation rule.
- SPARK-47609: Cached Plan lookup may miss picking valid plan
- SPARK-49618: canonicalization differences in Union may cause failure in re-use of exchange or cached plans.
- SPARK-49881: Minimizing the cost of DeduplicateRelations in the analyzer.
Functional Issues
- SPARK-47320: Self join inconsistencies and exceptions
- SPARK-49727: Data Loss issue when POJO Dataset is converted into DataFrame and back.
- SPARK-49789: Exception in encoding POJOs with generic type fields.
- SPARK-51016: Incorrect results during retry when joining column is indeterministic.
- SPARK-45658: Canonicalization of DynamicPruningSubquery is broken
- SPARK-53264: Incorrect nullability when correlated subquery gets converted to Left Outer Join
- SPARK-47217: DeduplicateRelations may cause failure in plan resolution
- SPARK-51016: Join on indeterminate column may give wrong results on retry
Why Choose TabbyDB?
With TabbyDB, you can expect not only a resolution to existing issues but also a significant boost in performance for your complex queries. Experience the difference today!
If you are facing any functional or performance bug in core spark or sql layer, we would be glad to solve the issue , for your apache spark code base too.
Just drop an email!
White Papers
-
Constraint Propagation Ruleconstraint propagation algo description List Item 1
Describes the new Constraint Propagation algorithm, which solves the issue of Constraints Blow Up due to permutational nature of the logic in stock Spark.
-
Capping the Query Plan sizecollapsing projects in analysis phase algo description List Item 2
Describes the idea of collapsing the project nodes in the analysis phase itself, there by preventing extremely large tree sizes for query plans created using Data Frame APIs
-
Pushdown of Broadcasted Keys as runtime filtersbroadcast var push down for file pruning List Item 3
Describes the runtime performance enhancement by utilizing the broadcasted keys as filters for file pruning, in case of non parttioned columns used as join keys
-
TPCDS Benchmark detailsTPCDS Benchmark Details
- Breakdown of the time taken.
- How the benchmark was conducted
- Configuration
Frequently Asked Questions about KwikQuery's TabbyDB
Find clear answers to common questions about TabbyDB’s capabilities, performance, and integration to help you make the most of our advanced query engine.
What makes TabbyDB different from standard Apache Spark?
TabbyDB is a specialized fork of Apache Spark designed to optimize complex queries. It significantly reduces compilation time and memory usage for queries with nested joins, complex case statements, and large query trees through intelligent compile-time and runtime enhancements.
Can TabbyDB handle extremely large and complex query trees efficiently?
Yes, TabbyDB is built to manage vast and intricate query structures. Its optimizations improve both the speed and resource consumption, enabling faster execution of queries that would typically take hours to compile and run.
Is TabbyDB compatible with existing Spark DataFrame APIs?
TabbyDB maintains full compatibility with Apache Spark’s DataFrame APIs, allowing corporate users to continue using their programmatic query methods while benefiting from enhanced performance without changing their existing codebase.
Ready to optimize your complex queries?
Download trial version TabbyDB-4.0.1 now!
You can even convert your existing Spark 4.0.1 to TabbyDB 4.0.1, by replacing existing jars. If you want to go back to apache spark 4.0.1, just remove the TabbyDB jars and bring back spark jars)
Contact us to evaluate the performance of your queries on TabbyDB